

-
Le Trameur
Au tout début de cette séance, on a fait connaissance avec deux nouveaux outils d’analyse de corpus : Gromoteur et Trameur. Pour nous trois, on a tous rencontré les problèmes quand on a voulu essayer d’utiliser le Gromoteur : ni le Windows ni le Mac n’a pas pu ouvrir cette application. De cela, on a seulement testé nos fichiers d’URLS avec petiMoteur, le module disponible dans le Trameur.
Après l’ouverture de cette application, on pourrait voir l’interface comme ce qu’indique la photo suivant :
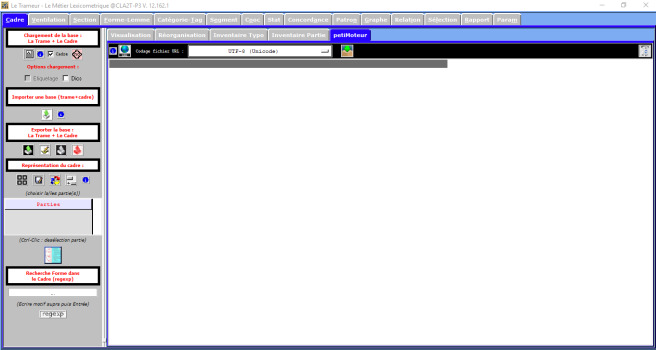
Dans la barre de menu, on cliquerait sur le bouton petiMoteur, et puis on cliquerait le bouton URL pour le chargement d’un fichier d’URL :
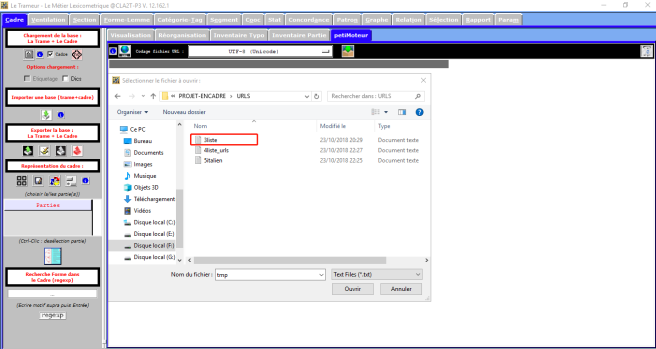
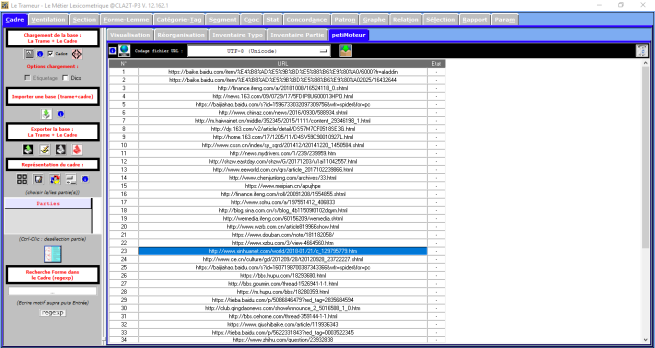
Après le bon chargement des fichiers d’URL, on cliquerait sur le bouton d’aspiration des URLs pour vérifier le contenu des URLs. Dans la colonne Etat, on obtiendrait les résultats, soit OK soit BAD. Au plus, dans le dossier d’URL, on aurait un fichier text_URLS qui comprendrait les pages aspirées.
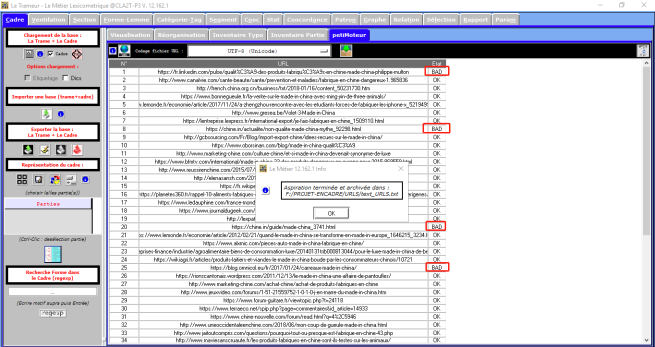
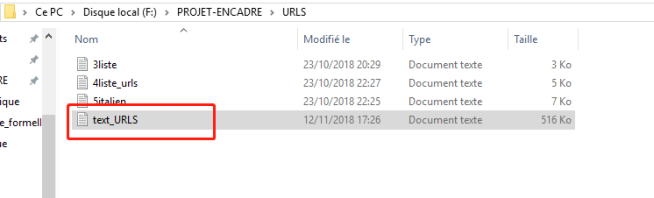
Pour les URLs qui ont obtenu le résultat BAD, il n’y a pas ses pages aspirées dans le fichier text_URLS, par exemple, notre premier URL français a été défini BAD, on n’a pas trouvé sa page aspirée, le fichier text_URLS commence par la page aspirée du deuxième URL.
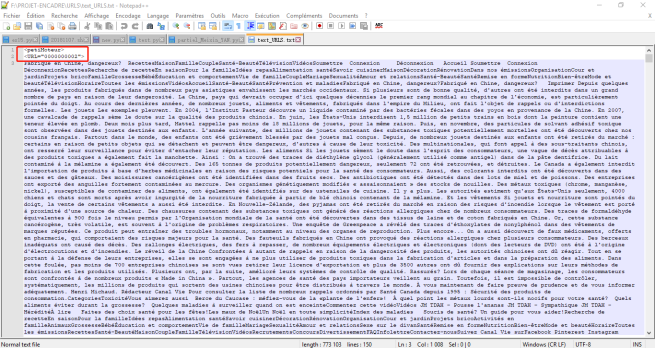
Afin de mieux afficher les résultats d’analyse de nos URLs, on a fait le tableau suivant :
Ensuite, entre nous trois, on a discuté sur les raisons pour lesquelles les URLS ont été définis BAD. Premièrement, on suppose que ces pages n’existeraient plus. Pour vérifier ça, on a ouvert les urls bad avec le navigateur, les urls français No.1/8/20/44 se sont ouverts sans erreur, par contre, l’url No.25 a obtenu ce résultat « 404 That page hasn’t been created yet. It appears that page doesn’t exist. Try some of these latest posts or a search. ». Les urls italiens No.66/67 se sont ouverts aussi sans erreur, mais l’urls No.44 a eu ce résultat «ERR_CONNECTION_TIMED_OUT ». Deuxièment, pour les urls BAD qui n’ont eu aucune difficluté d’être ouverts, on déduit que quelque chose de bizarre dans le langage du blog a empêché le décodage d’URL ou à l’intérieur de l’URL, il n’y a pas d’informations sur l’encodge. Pour le moment, on supprime les URLS qui s’ouvrent pas et on conserve encore les URLS avec problème, on va trouver la solution avec les cours qui suivront.
-
Le script
Dans le script du 10 octobre, on a appris comment établir un tableau qui comprend deux colonnes, une colonne de compteur et l’autre colonne de chaque ligne dans un fichier d’URL. Sur le script de la scéance dernière, on ajouterait deux nouvelles colonnes, l’une des pages aspirée, l’autre d’encodage.
Les Ajouts et modifications de cette scéance :
- Lire un fichier d’URLS en plusieurs;
- Afficher chaque URL dans une ligne d’un tableau;
- Ajouter une colonne pour numéroter les URLS;
- Créer un lien hypertexte pour chaque URL;
- Ajouter une colonne contenant « la page aspirée » pour chaque URL;
- Trouver l’encodage de la page.
Le script de cette scéance :
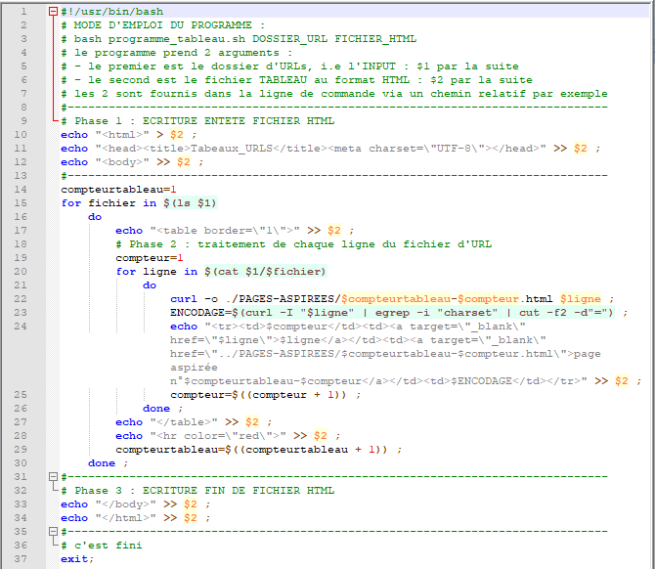
Pour parcourir tous les fichiers dans le dossier des URLs, on a ajouté un boucle de for dans le script. On a aussi donné un variable de compteurtableau pour distinguer nos trois corpus. Et pour numéroter les URLS dans un certain corpus, on a choisi un autre variable compteur, après chaque fois de traitement, le variable augmenterait de 1.
Mais pour aspirer les pages du web, il est un peu plus difficile. On va utiliser une nouvelle commande curl avec l’option – o et on mettra les pages aspirées dans le fichier PAGES-ASPIREES :
Curl est un outil de téléchargement dont la grammaire est comme le suivant:
curl [option] [url]
L’option -o désigne la mode d’output.
Et pour trouver l’encodage d’une page de web, on ne peux non plus éviter d’utiliser la commande curl, mais avec l’option -I qui sert à retourner seulement l’entête d’une page de web. Dans ce cas, on obtient en général une partie du contenu de web qui comprend non seulement l’information d’encodage. Mais c’est que l’information de charset qui nous intéresse, alors on utilise la commande egrep avec l’option -i pour chercher les informations dont on a besoin en négligeant l’écriture des mots, en général, on obtient « charset=utf-8 ». Pour que seulement le mot « utf-8 » apparaisse dans le tableau, on utilise « cut -f2 -d »= » » afin de couper les mots inutiles et garder l’encodage utile.
On exécute ce script dans le cygwin :

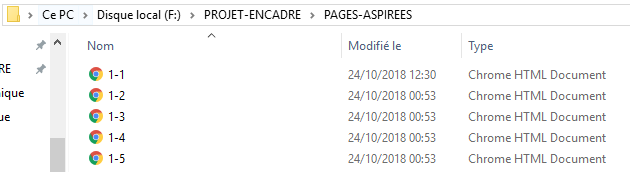
Après l’exécutation du bash, on obtient un tableau qui affiche bien les résultats pour nos 3 fichiers d’URLs :

Voilà voilà, c’est la séance du 17 octobre, on a appris pas mal de choses. Dans le tableau de cette séance, on pourrait remarquer que pour certains urls, il n’affiche pas l’encodage, on va résoudre ce problème dans la scéance prochaine. A la prochaine!
Meixin, Andréa, Pierre
