

Nous continuons le développement de notre script Bash. La séance du 24/10/18 nous a essentiellement permise d’intégrer deux conditions : Une première pour vérifier la validité de nos liens, et une autre afin vérifier l’encodage des sites. Elle a également été l’occasion d’introduire une commande particulièrement puissante : « lynx » afin de récupérer le contenu de nos sites internet sous forme de texte brut.
Environnement (Pierre) : Système : Windows / Editeur : Sublime Text
I. Vérification de la validité des sites
D’abord nous allons récupérer pour chaque lien le code de la connexion HTTP correspondant, c’est ce code qui nous indique si un site fonctionne correctement ou s’il est non valide.

Pour procéder nous mettons dans la variable code_sortie le résultat de l’enchaînement de deux commandes :
- curl (que nous avions déjà eu l’occasion d’utiliser pour la variable ENCODAGE)
Les options :
- -o permet de rediriger la sortie dans un fichier nommé tmp.txt
- -w permet de détecter l’information demandée : ici le code par la syntaxe « %{http_code}
- tail permet normalement de récupérer les dix dernières ligne du contenu. Mais en ajoutant l’option -1, on récupère seulement la dernière ligne.

Une fois le code récupéré, nous insérons une condition pour vérifier la validité du site. Si le code est égal à 200 alors le site est valide et nous continuons le traitement de ce site : if [[ $code_sortie == 200 ]] then …
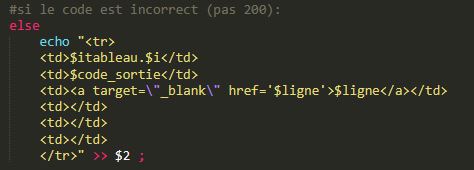
Si le code n’est pas égal à 200 alors cela signifie que la connexion HTTP a rencontré un problème. Dans ce cas nous n’effectuons pas la suite du traitement.
Concernant l’affichage dans le tableau nous laisserons donc des cellules vides pour les colonnes suivantes : aspiration de la page, encodage et dump-text (Ces traitements n’ayant pas été effectués). Nous afficherons néanmoins le numéro du lien ainsi que le code de la sortie pour reconnaître les sites non-valides.
Remarque : Nous expliquons le dump-text dans la troisième section de l’article.
II. Vérification de l’encodage
Pour la suite du traitement nous ne pourrons exploiter seulement les sites encodés en UTF-8. Nous devons donc vérifier l’encodage de chacun des sites afin de savoir si un traitement préalable doit être effectué sur les sites non encodés en UTF-8. (Nous verrons dans les séances suivantes comment effectuer une éventuelle conversion de l’encodage).

Comme vu précédemment nous continuons le traitement seulement pour les URLS valides.
Nous avions déjà récupéré l’encodage dans une version précédente du script. Il suffit maintenant d’insérer une condition pour vérifier si l’encodage récupérer est UTF-8. Avant cela nous complétons la ligne de récupération de l’encodage avec la commande tr afin de l’uniformiser (en majuscule).
- tr permet de remplacer des caractères par d’autres. Ici nous utilisons cette fonction afin de remplacer toutes les lettres minuscules comprises entre a et z (donc les lettres de l’alphabet non diacritées) par les mêmes lettres en majuscules.
Pour bash une lettre minuscule est différente d’un lettre majuscule, cette opération est donc indispensable pour bien effectuer la vérification.
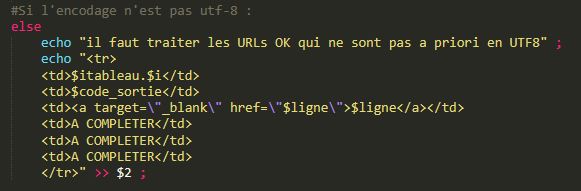
Nous pouvons ensuite vérifier la condition : si l’encodage est égal à UTF-8 alors nous continuons le traitement : if [[ $ENCODAGE== »UTF-8″ ]] then …
Nous apprendrons dans la séance suivante comment convertir les encodages. En attendant nous laissons un message nous rappelant de traiter prochainement les URLS qui ne sont pas encodés en UTF-8 et nous affichons « A COMPLETER » dans les cellules du tableau correspondantes. Ces URLS seront traitées dans la prochaine mise à jour du script.
III. Intégration de la commande lynx pour récupérer le dump-text
Lynx est un navigateur web utilisable depuis le terminal Bash. En lui fournissant un URL lynx affiche le texte de la page web correspondante.

En ajoutant l’option -dump à la commande lynx on en fait un outil particulièrement puissant. Le couplage lynx -dump permet de récupérer le contenu « texte » de la page web, sans les balises html, le code javascript ou autres informations présent dans le code source d’une page web.
Ici, on ajoute cette commande après avoir vérifié le code http de l’URL (afin d’aspirer seulement les pages valident).
On ajoute également l’option -nolist afin d’indiquer à la commande de ne pas suivre les liens potentiellement présents sur le page web. En effet sans cette option, lynx -dump aspirerait également le contenu des liens présent sur la page web.
Toutes les pages aspirées avec lynx -dump sont envoyé vers le dossier « DUMP-TEXT »
IV. Problèmes rencontrés et anticipation sur l’évolution du script
Si nous ouvrons un de nos fichiers DUMP-TEXT provenant d’une page web écrite en chinois nous remarquons rapidement que les caractères sont mal encodés. Il semblerait que ce problème concerne les pages-web non encodées en UTF-8. Dans la suite du script il faudra donc agir sur les pages valide (code HTTP = 200) en commençant par faire une conversion de l’encodage.
Un autre problème concerne les URLs valident mais dont l’encodage n’a pas pu être récupéré. Si le site est valide alors il possède obligatoirement un encodage. Si nous n’avons pas pu le détecter alors cela signifie que la méthode que nous avons utilisé n’est pas infaillible. Elle est sans doute inefficace pour les pages html qui ont mal respecté les conventions syntaxiques. On trouvera donc une solution pour forcer la détection de l’encodage.
Bientôt la suite !
Meixin, Andrea et Pierre
