

On est arrivé presque à la fin du projet!
Dans cette nouvelle scéance, on va insérer de nouveaux traitements au corpus:
1. Extraction de contextes « courts » autour des mots choisis;
2. Comptage de la fréquence des mots choisis dans chaque fichier dump;
3. Création d’un index des mots présents dans chaque fichier dump;
4. Calcul de bigramme…
Après quelques essais avec nos trois corpus, on s’est rendu compte que le chinois ne devrait pas être traité de la même manière que le français et l’italien. Le chinois appartient à une autre famille de langue dont les règles sont totalement différentes des langues latines. Dans la langue chinoise, on n’utilise pas les lettres latines pour écrire, de plus, on n’utilise pas les espaces pour séparer les mots l’un avec l’autre. De cela, la façon de trouver le contexte, la fréquence et l’index des motifs dans le français ne fonctionne pas très bien dans le chinois.
Pour résoudre ce problème, on a demandé à l’aide aux professeurs et aussi après avoir discuté avec les camarades, on a décidé d’avoir recours à l’outil de segmentation du chinois: Stanford Chinese Segmenter.
C’est une application qui est capable de segmenter le chinois en une séquence de mots basée sur le CRF(conditional random fields, en français, champ aléatoire conditionnel). On pourrait consulter cet article pour plus de détails: http://nlp.stanford.edu/pubs/sighan2005.pdf
INSTALLATION
Cliquez ce lien pour télécharger: https://nlp.stanford.edu/software/segmenter.shtml
USAGE
La mode d’utilisation est comme le suivant:
> segment.sh [-k] [ctb|pku] <filename> <encoding> <size>
Dont:
ctb: Chinese Penn Treebank standard
pku: Peking University standard.
filename: le fichier à segmenter
encoding: UTF-8 etc.
size: juste entrez ‘0’
k: garder toutes les espaces dans les fichiers à segmenter
Cependant, on n’a pas arrivé à faire fonctionner ce bash sur cygwin de Windows, donc on a essayé avec le Virtualbox.
Exemple
Après qu’on démarre l’ubuntu avec le Virtualbox, on ouvre le terminal pour taper les commandes. Mais comme on est sur un autre système, Ubuntu, qui est différent du système de notre ordinateur, Windows, alors il faut d’abord partager les dossiers de notre machine sur Ubuntu. Cliquez sur Périphériques-Dossiers partagés-Réglage des dossiers partagés, sous les « Dossiers permanents », ajoutez un chemin de dossier qu’on voudrait prendre pour le dossier partagé, et lui donnez un nom, ex. share, F:\share. Et il vaut mieux copier le dossier du projet dans ce dossier partagé.
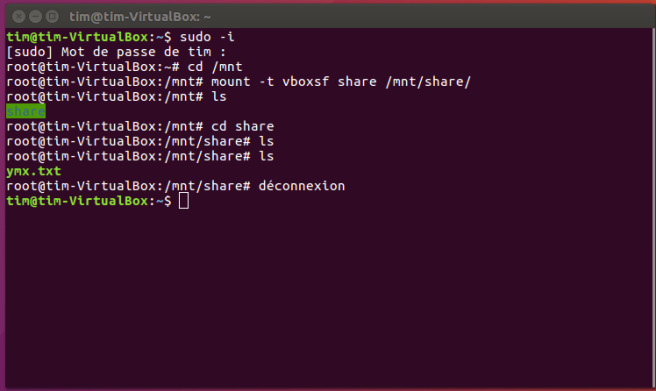
Ensuite, on va lier Windows avec Ubuntu, pour faire cela, on a besoin de quelques lignes de commandes:
sudo -i
cd /mnt
mount -t vboxsf share /mnt/share/
cd share
ls
Si on peut voir notre dossier du projet apparaître dans la liste, il prouve qu’on a bien fait le travail. Ctrl+d pour l’étape suivante.
Pour utiliser le segmenteur du chinois, on ajoute une ligne de commande dans le script du projet:
bash ./stanford-segmenter-2018-10-16/segment.sh -k ctb ./DUMP-TEXT/$compteurtableau-$compteur.txt UTF-8 0 ;

Voilà c’est comment on a segmenté le chinois pour faciliter le travail suivant. À la prochaine!
Meixin, Andréa, Pierre
