

Dans cette séance nous avons complété notre script avec plusieurs fonctions afin de créer des informations supplémentaires concernant notre occurrence « made in China ». Nous avons également intégré le minigrep : un programme écrit en langage perl. Les colonnes du tableau seront évidement adaptées.
Environnement (Pierre) : Système : Windows / Editeur : Sublime Text 3
D’abord observons une partie du script contenant ces nouvelles commandes :

Chaque nouvelle ligne permet d’obtenir de nouvelles informations concernant les données récoltées à partir de nos URLS.
Le contexte

Pour récupérer le contexte nous utilisons la commande egrep. Ici, à partir du fichier .txt présent dans le répertoire DUMP-TEXT, egrep va récupérer les lignes contenant le paramètre $3. La variable $3 correspond au troisième argument donné lors du lancement du script. Nous n’oublierons donc pas de préciser notre mot clé « made in China » en $3. L’option -i permet notamment d’ignorer les différences majuscules / minuscules.
Nous indiquons également la sortie de la commande : un fichier .txt que l’on place dans le répertoire CONTEXTES.
Voici un exemple de ce qu’on peut obtenir dans notre fichier en sortie :

La fréquence du motif

Nous cherchons ici le nombre de fois qu’apparaît notre mot clé.
Nous utilisons également la commande egrep avec en entrée le même fichier .txt présent dans le répertoire DUMP-TEXT. Nous ajoutons cependant deux options :
-c qui permet de compter les occurrences (ce que nous voulons)
-o qui permet de renvoyer seulement le mot clé donné en paramètre et non la ligne entière. Ainsi si l’occurrence est présente deux fois sur la même ligne alors c’est autant de fois qui seront ajouté au compteur.
Nous dirigeons le résultat dans la variable nbmotif. Ceci nous permettra de l’appeler plus tard pour afficher le résultat dans une des colonnes de notre tableau.
Le contexte HTML

Pour le contexte html, nous avons simplement exécuté un programme perl appelé « minigrep ». Par simplicité et par manque de temps nous utilisons le perl pour windows (version 5.28.0)
- Nous avons télécharger l’archive minigrep
- Ensuite nous le décompresson dans le dossier de travail de notre projet
- Puis nous remplacons le contenu présent dans le fichier parametre-motif.txt par « MOTIF=\bmade in China|中国制造\b »
Une fois ce processus terminé nous pouvons exécuter le programme.
Initialement le programme perl enregistre le résultat dans « extraction-extraction.html », nous utilisons donc la commande mv pour le déplacer dans le dossier CONTEXTES et le renommer.
L’index hiérarchique

Nous passons maintenant à un enchaînement de plusieurs commandes où la sortie de la précédente devient l’entré de la suivante.
- Nous commençons par egrep -o « \w+ » (toujours sur le même fichier .txt) : Nous connaissons déjà l’option -o expliqué ci dessus. « \w+ » est une expression régulière. Le « \ » est le délimiteur. Le « w » marque la présence d’un caractère alphanumérique et le + signifie « 1 à n fois le le caractère précédent ». Cette syntaxe permet donc de détecter les mots (définies par les espaces) peut importe leur taille et leurs caractères. Avec la commande egrep, nous récupérons donc tous les mots présents dans le fichier.
- sort va ensuite trier les mots récupéré.
- uniq va supprimer les doublons. On l’accompagne de l’option -c va afficher en début de ligne le nombre d’occurrence du mot.
- Enfin on utilise sort pour retrier les mots en ajoutant cette fois l’option -r qui va trier en fonction de la valeur numérique de la ligne. Ici il s’agit du nombre d’occurrence.
On envoie le résultat dans un fichier que l’on stocke dans le répertoire DUMP-TEXT
Voici un exemple de ce qu’on peut obtenir dans notre fichier en sortie :
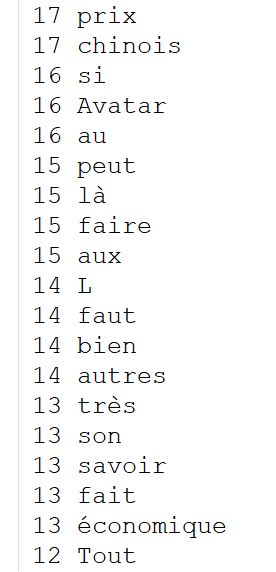
Remarque : Si cette méthode fonctionne bien pour le français et l’italien, il convient de remarquer qu’il est inefficace sur le chinois. En effet le chinois n’utilisant pas les espaces pour délimiter les mots, il est difficile d’établir une expression régulière adaptée.
Le Bigramme

Pour faire notre trigramme nous utilisons plusieurs commandes.
- D’abord nous réutilisons la commande egrep -o « w+ » afin de récupérer tous les mots présents dans le fichier DUMP-TEXT. Nous les enregistrons dans le fichier bi1.txt
- Nous utilisons la commande tail afin de recopier le contenu du fichier bi1.txt dans bi2.txt sans la première ligne. En effet, tail recupère normalement les dix dernières lignes d’un fichier, mais en ajoutant l’option -n nous pouvons récupérer le contenu à partir de n’importe quel ligne. Il suffit seulement de préciser le numéro de la ligne. Nous écrivons donc tail -n +2 afin de récupérer le contenu à partir de la deuxième ligne.
- La commande paste nous permet ensuite de fusionner chaque ligne des fichiers bi1.txt et bi2.txt. Nous enregistrons le résultat dans bi3.txt.
- On termine par une dernière ligne dont nous avons déjà expliqué l’enchaînement de commandes : cat pour éditer le contenu du fichier bi4.txt / sort pour le trier / uniq -c pour compter et supprimer les doublons / sort -r pour retrier en fonction du nombre d’occurrence.
On redirige la sortie vers un fichier .txt placé dans le répertoire DUMP-TEXT.
*
Il ne faut pas oublier d’afficher les résultats du traitement dans les colonnes respectives du tableau :

*
On intègre toutes ces fonctions dans chaque partie où nous devons effectuer le traitement, c’est à dire après avoir détecté l’encodage UTF-8 ou bien après avoir converti l’encodage initial. Il y a plusieurs adaptations à faire :
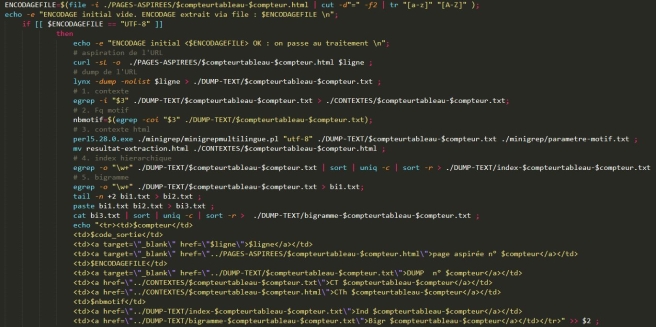
- A chaque fois que nous détectons l’encodage grâce à la commande file.
Par exemple :
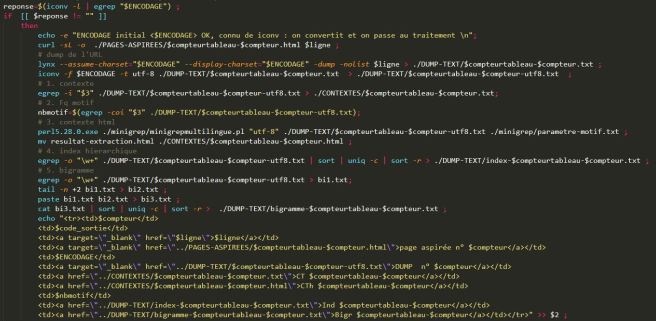
- A chaque fois que nous convertissons l’encodage.
Par exemple :
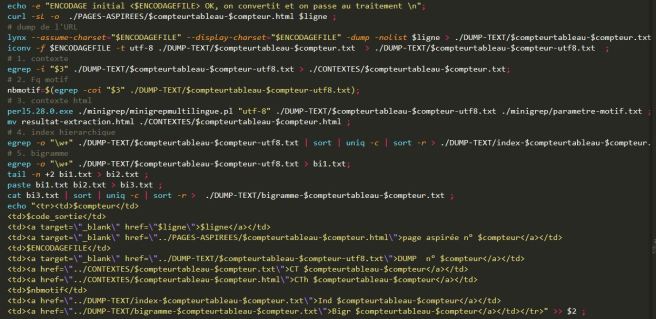
- A chaque fois que nous faisons les deux (encodage détecté avec file et conversion).
Par exemple :
***
Il nous reste encore quelques problèmes à régler mais mous approchons de la fin du script !
Meixin, Andrea et Pierre
