

Le corpus que nous nous apprêtons à analyser est le produit final généré par notre programme principale. Il s’agit d’une récolte de textes provenant d’internet (lire aussi notre article sur la recherche des URLs) qui ont été concatené dans un seul fichier et balisé en sous-parties.
Pour l’analyse du corpus en italien nous avons utilisé le iTrameur (développé par Serge Fleury, Université Paris III) et AntConc (développé par Laurence Anthony, Waseda University), deux outils d’analyse textométrique.
Puisque nous avons décidé d’analyser un syntagme et non pas un mot, nous avons d’abord converti toutes les formes composées “Made in China” dans une forme normalisée: “made_in_china”. Ce changement nous a permis d’aplanir les différences orthographiques / typographiques et d’optimiser les résultats dans l’iTrameur.
Avant de plonger dans l’analyse linguistique, il peut être intéressant d’examiner les données du corpus italien de manière macroscopique. AntConc permet d’importer une liste de stop-words et de générer en sortie une liste de fréquence normalisée. Voici alors un aperçu sur nos données :
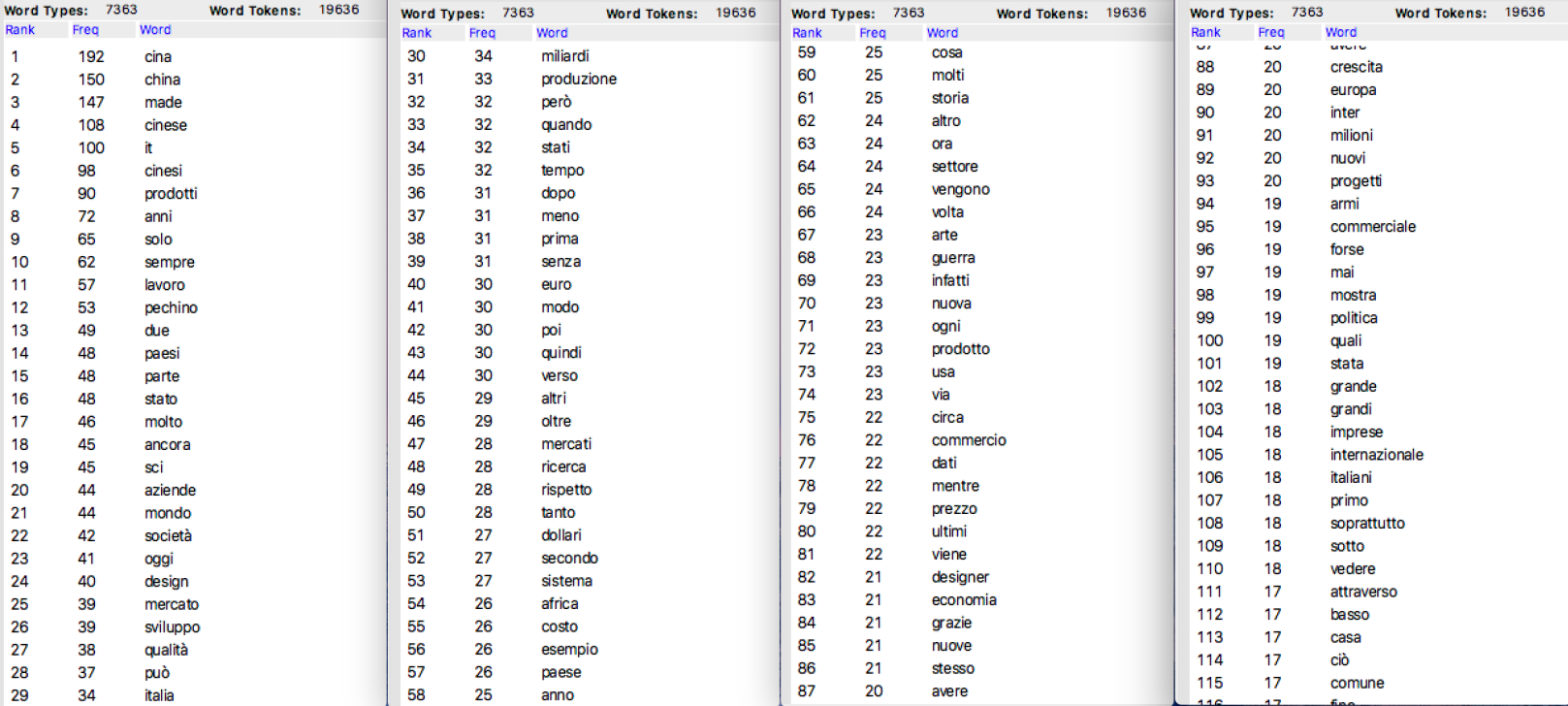
Parmi les mots récurrents, nous pouvons citer : « produits », « travail », « Pékin », « entreprises », « société », « design », « développement », « qualité », « production », « marchés », « prix », « guerre »… Des mots qui soulignent très clairement les liens historiques, commerciales ansi que les domaines de coopérations entre la Chine et l’Italie.
Pour avoir une vision plus concrète sur le champ sémantique lié au syntagme en question, nous cherchons les cooccurrents de “made_in_china”. Voici les résultats obtenus grâce à iTrameur :
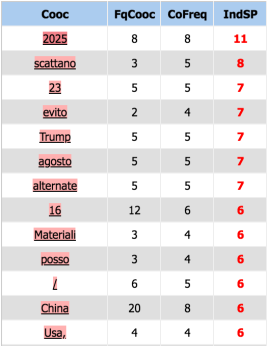
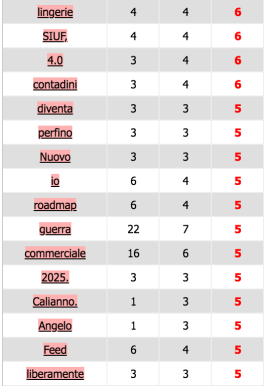
iTrameur permet de calculer l’index de spécificité (IndSp, troisième colonne) des mots liés au made in china et de les représenter sous forme de graphe.
Voici une représentation en graphe:
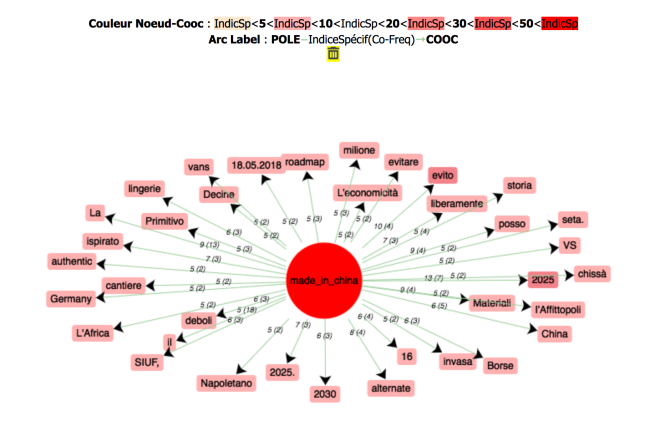 Les liens récoltés contiennent principalement des articles de journaux, des articles d’opinion, des critiques de films ainsi que des forums. On peut voir que les mots associés sont diverses mais toute à fait liés à nos hypothèses initiales.
Les liens récoltés contiennent principalement des articles de journaux, des articles d’opinion, des critiques de films ainsi que des forums. On peut voir que les mots associés sont diverses mais toute à fait liés à nos hypothèses initiales.
Dans notre échantillon le syntagme est surtout associé à des domaines telles que :
- le commerce : « matériaux », « soie », « vans » (un type de chaussures), « lingerie » ;
- l’économie et la politique : « 2025 » (qui fait référence au Made in China 2025, un plan économique à atteindre d’ici 2025), « roadmap », « bourse » ;
En outre, nous pouvons remarquer la présence de mots qui n’appartiennent pas aux domaines déjà mentionnés et qui sont moins neutres ou même connotés négativement. Un exemple de ce genre est le verbe « éviter« . AntConc permet d’isoler en concordance plusieurs formes d’un même lemme, grâce aux expressions régulières. On sélectionne alors les formes les plus fréquentes du verbe éviter:

Ce sont visiblement des commentaires des internautes qui discutent entre eux dans les forums pour recevoir ou donner des conseils sur les produits à acheter ou récemment achetés en ligne.
Hit 1: « Au début, moi aussi je voulais éviter les produits « made en chine », mais cela devient de plus en plus difficile ».
Ou encore:
Hit 3: « Je refuse d’acheter des skies « made en chine », si j’en ai la possibilité, j’évite le « made en chine »… ».
Notre intuition est qu’en Italie, les produits fabriqués et importés de Chine sont considérés comme un danger potentiel pour la production nationale, parce qu’ils sont généralement plus compétitifs par rapport aux produits italiens. De l’autre part, nous avons assisté au développement d’une idée reçu selon laquelle les produits chinois seraient de qualité inférieure à ceux qui sont fabriqués en Italie.
La présence phénomène des importations massives est documenté par les nombreux articles de journaux, dans lesquels « Made in China » est souvent associé à la contrebande et à la saisie de marchandises irrégulières.
Un zoom sur les formes liées à la racine « sequestr- » (en français : confisquer, saisi) :
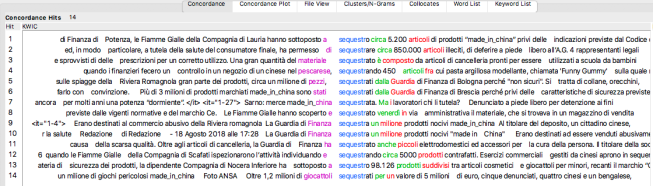
Hit 1: « Potenza [ville], la brigade financière a saisi environ 5.200 produits « made in China » sans les indications prévues par le Code… »
Hit 8: « Plus de 3 millions de produits marqués « made in china » ont été confisqués par la brigade financière de Bologne car « dangereux ». […] ».
Un autre mot qui a attiré notre attention est le nom d’un vin de production italienne, le « Primitivo« . On lance donc une concordance dans l’iTrameur.
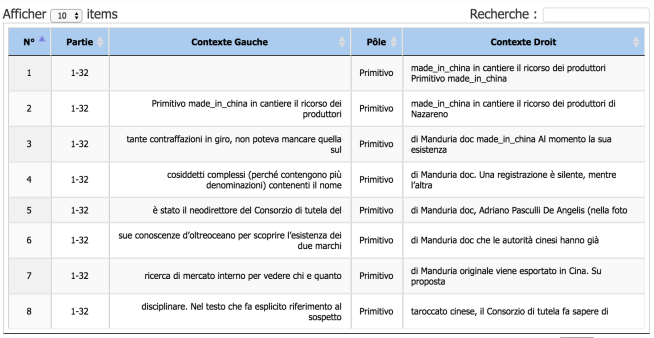 L’avantage d’avoir préalablement balisé notre corpus est que nous pouvons voir clairement quelles sont les sous-parties concernées par la concordance. Tous les occurrences du mot « Primitivo » proviennent d’une même partie, le fichier 1-32.txt. Effectivement, cette partie contient le dump d’un article de journal traitant le sujet de la contrefaçon du vin italien par une entreprise chinoise.
L’avantage d’avoir préalablement balisé notre corpus est que nous pouvons voir clairement quelles sont les sous-parties concernées par la concordance. Tous les occurrences du mot « Primitivo » proviennent d’une même partie, le fichier 1-32.txt. Effectivement, cette partie contient le dump d’un article de journal traitant le sujet de la contrefaçon du vin italien par une entreprise chinoise.
Ainsi pour conclure cette analyse, nous avons pu constater que nos hypothèses initiales pour la partie italienne du corpus sont confirmées. Le corpus a fait émerger très clairement la forte présence économique et commerciale de la Chine en Italie, une présence qui est à la fois appréciée, vu le prix bas des marchandises vendues, mais critiquée étant donnée la basse qualité des produits.
Nous tenons à préciser que cette étude a été mené sur un petit échantillon et que les donc les résultats peuvent changer en fonction de la grandeur et de la représentativité du corpus. Cependant, les connotations observées semblent être suffisamment répandues pour pouvoir justifier cette analyse.

