

Cet article, il s’agit d’une analyse de notre corpus en chinois, généré du script qui est complété petit à petit durant tout le semestre. On se rappelle que l’objectif du projet est de faire une étude textométrique d’un certain mot. Pour notre groupe, il s’agit bien d’un terme, « made in China »(en chinois, 中国制造/制造中国) et on voudrait bien trouver les émotions des gens par rapport aux produits « made in China » en ayant recours aux méthodes talistes. Dans cet article, on va montrer les statistiques qu’on a obtenues et on va donne une réponse à la problématique.

Pour l’analyse nous utilisons iTrameur (développé par Serge Fleury, Université Paris III) et AntConc (développé par Laurence Anthony, Waseda University), deux outils d’analyse textométrique.
- Pré-entraînement du corpus
Pour notre groupe, il s’agit d’une étude d’un syntagme, pas d’un seul mot, donc afin d’optimiser les résultats obtenus avec les outils, on va amener quelques changements au corpus. Mais on voudrait quand même éclairir que dans les articles chinois et dans les réseaux sociaux chinois, les gens utilisent aussi l’anglais « made in China » pour exprimer leurs opinions. Pour englober toutes les possibilités de résultats, on va traiter « made in China/中国制造/制造中国 » comme les mots clés. Tout comme le corpus italien et français, on va convertir « made in China » en « made_in_china ». Et pour les mots correspondant en chinois, on pourrait voir qu’après la segmentation avec le stanford segmenter, « 中国制造 », cette expression qui est composée de quatre caractères est divisée en deux mots de deux caractères: « 中国(in China) » et « 制造(made) ». Alors on décide d’enlever l’espace entre les deux mots, comme ça, on obtient un terme complet. Pour faire tout cela, on utilise la fonction « rechercher-remplacer » dans le Notepad.
- AntConc
D’abord, on essaie avec l’application AntConc. Après avoir ouvert le corpus (le texte après la concaténation de tous les textes de dump) dans le logiciel AntConc, on pourrait obtenir une liste de mots dans le texte:
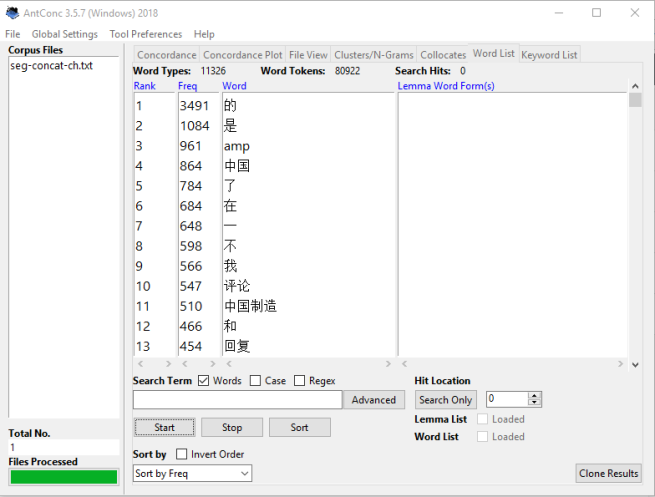
On pourrait observer dans la liste que la fréquence des stop words est trop élevé, alors on va importer une liste de stop words en chinois(téléchargé sur Internet) pour que le logiciel puisse exclure le plus possible les mots inutiles.
Après avoir fait cela, on a les résultats différents et en plus bonne qualité. La fréquence des mots est comme le suivant:
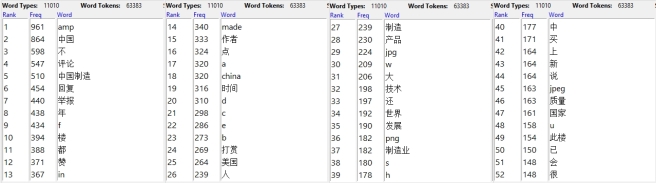
Il y a une possibilité d’écriture du motif « made in China » en chinois qui se trouve en avant de la liste, plus précisément, au cinquième de la liste avec une fréquence de 510. Dans la liste, on peut quand même voir que « made », « in » et « china » apparaissent séparément, même si on a déjà fait le pré-entraînement du corpus, et pour les motifs en chinois, c’est le même cas, le terme est encore séparé en deux parties.
Quand on veut trouver la concordance des motifs dans le texte, le logiel nous renvoie le résultat comme le suivant:
==>pour le motif « 中国制造 »:
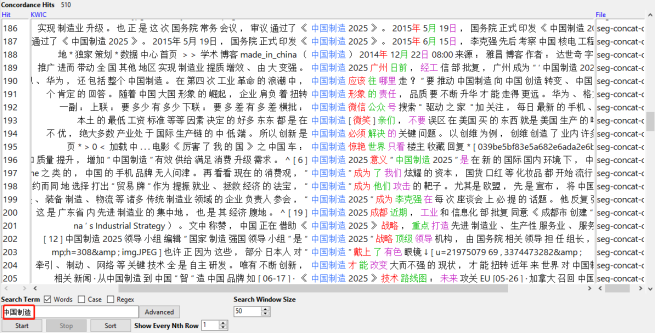
On peut voir qu’on a trouvé 510 concordances et leurs contextes dans le texte.
==> pour le motif « 制造中国 »:
Par contre, il y a 0 concordance pour cette écriture du motif en chinois. Alors on pourrait exclure cette possibilité d’écriture des motifs.
==>pour le motif « made_in_china »:
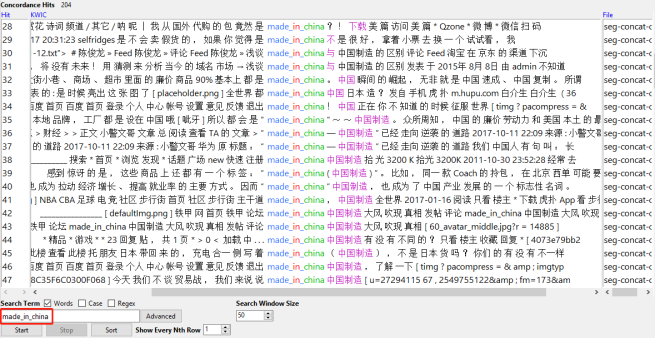
On a trouvé 204 concordances pour « made_in_china ».
Jusqu’à maintenant, il est encore difficile de conclure les émotions envers « made in China », alors on essaie encore avec la rubrique « N-Grams ». Quand on met « 中国制造 » dans le logiciel, il nous donne ce résultat:
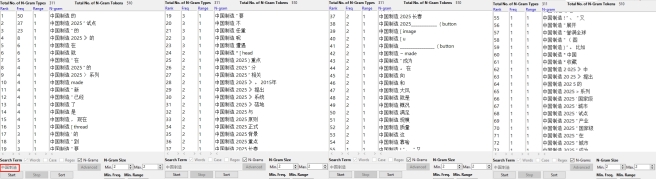
On trouve qu’il reste encore des stop words qui influent beaucoup les résultats, mais à part ça, parmi les 100 premiers résultats, on peut quand même trouver:
Le « 中国制造(en anglais, made in China) » est lié énormément avec le « 2025 », le terme « 中国制造2025 », il s’agit d’une politique économique chinoise qui vise à développer l’industrie de fabrication de la Chine.
On a trouvé aussi au 57ème de la liste un résultat: « 中国制造誉满全球 », qui veut dire que le « made in China » est connu du monde entier. Cela peut quand même nous aider à prévoir un peu les émotions des Chinois, on pourrait faire une hypothèse que la plupart des Chinois sont fiers de leur pays et des produits fabriqués en leur pays.
Quand on met « made_in_china » dans la case de recherche, le logiciel n’a pas renvoyé un résultat de valeur:
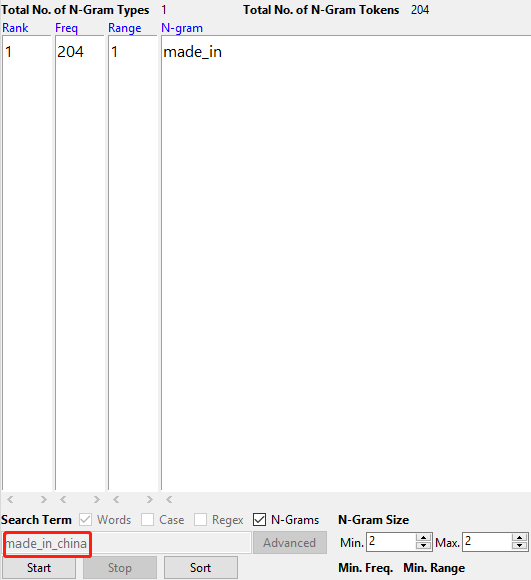
- iTrameur
Pour avoir une analyse plus raffiné, on importe le corpus dans l’iTrameur. Mais pour le bien de la qualité des résultats, on va nettoyer les données avant cette importation. Puisque une moitié des données de notre groupe viennent des forums sur Internet, les formats des forums composent des bruits pour l’analyse. De plus, les publicités sur les pages de web composent une autre partie des bruits pour l’analyse. Alors on va faire un peu le nettoyage avec Notepad. Après cette étape de nettoyage, on met le corpus dans l’iTrameur:
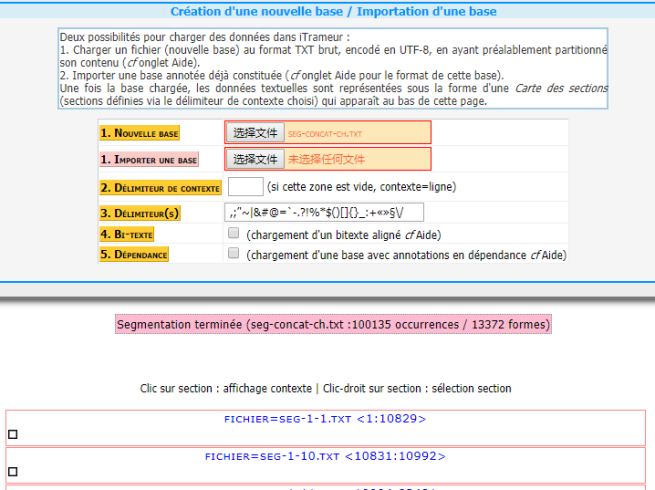
Trame-Dictionnaire
pour le motif « 中国制造 »:
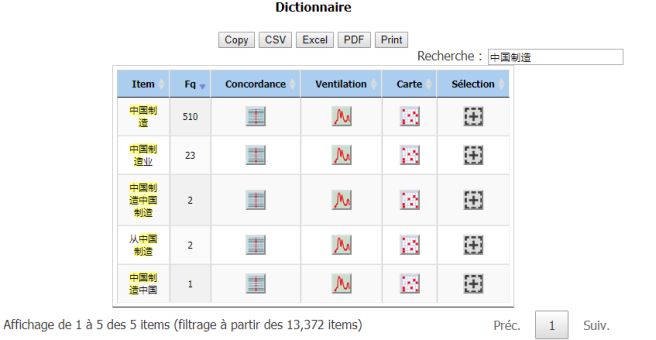
On peut trouver que la présence du motif « 中国制造 » est remarquable dans le corpus, avec une fréquence de 538(=510+23+2+2+1).
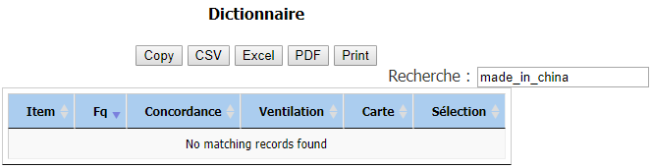
pour le motif « made_in_china »:
On n’a pas obtenu un résultat intéressant avec ce motif:
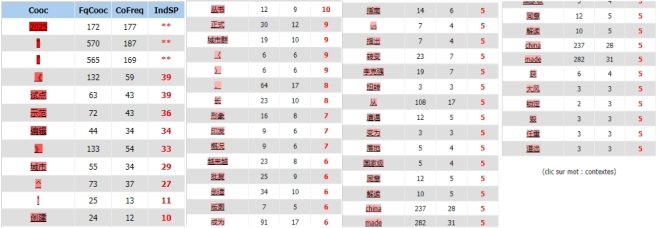
Coocs-cooccurrents
Quand on met « 中国制造 » dans le paramètre, l’iTrameur nous donne le résultat suivant:
Le graphe associé est:
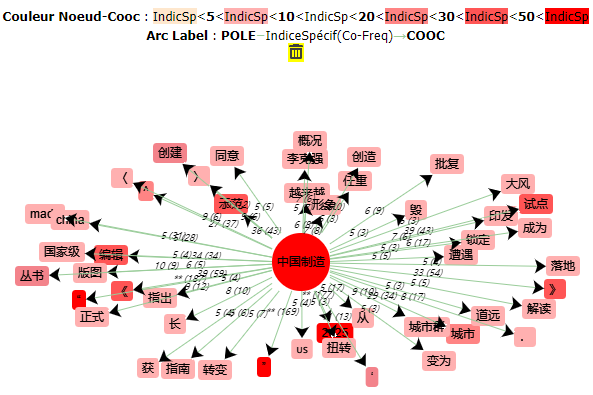
On remarque encore qu’il y a des stop words, par exemple, les ponctualitions, qui occupent une grande partie du résultat.
- Analyse des statistiques
À partir des résultats d’analyse ci-dessus d’iTrameur, on pourrait extraire quelques mots qui sont des occurrents de « 中国制造 », qui ont beaucoup de sens et qui nous aident à répondre à la problématique du projet.
2025
Ce chiffre apparaît souvent avec notre mot clé chinois, comme ce qu’on a déjà expliqué, c’est un slogan qui est proposé par le premier ministre de la Chine. En gros, il s’agit d’une politique économique qui renforce l’industrie de fabrication de la Chine.
Nos articles chinois sont extraits de l’Internet il y a pas beaucoup de temps, donc on peut comprendre que les articles récents correspondent aux mesures politiques. En tout cas, c’est une politique qui amène du bien au peuple chinois, c’est normal aux internautes d’en discuter souvent et beaucoup sur Internet.
创造(création/créer)
Si on utilise l’iTrameur pour voir les contextes à gauche et à droite de ce mot, on peut obtenir un tableau comme le suivant:
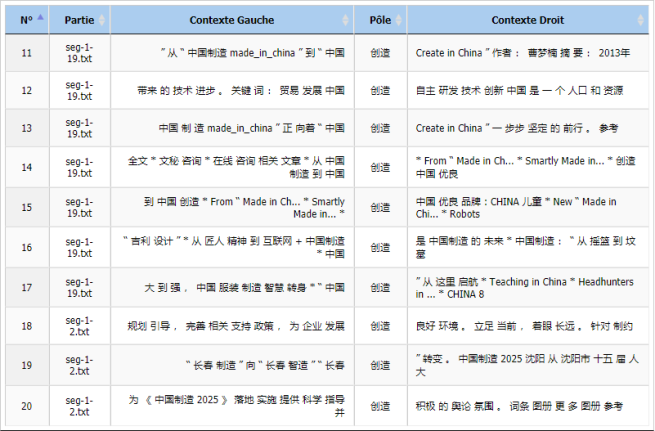
Après avoir vérifié toutes les concordances de ce mot dans le corpus, on peut trouver que les gens sur Internet parlent de la transition de « 中国制造(made in China) » vers « 中国创造(creation in China) ». Il s’agit d’un jeu de caractères en chinois. Dans ces deux termes, il n’y a qu’un caractère qui diffère, mais leurs sens sont totalement différents. À travers ce nouveau terme « 中国创造(creation in China) », on peut sentir que les Chinois attendent beaucoup de l’industrie de leur pays, qu’ils sont optimistes du futur.
转变(transformation)
Il s’agit aussi du changement de l’industrie e fabrication de la Chine. Depuis longtemps, la Chine est appelée l’usine du monde, les gens veulent qu’il y aient des changements sur cette situation. On ne satisfait plus à fabriquer les produits, dans le futur, on va mettre plus d’énergies à créer de nouvelles technologies, on va avoir plus d’outputs intelligents.
越来越(de plus en plus)
Après qu’on observe les contextes de cet adverbe, on trouve qu’il modifie souvent l’adjectif « 好(bon) ». On pourrait encore une fois sentir l’espoir des Chinois sur le futur de « made in China ».
- Conclusion
Avec l’aide de deux outils d’analyse textométriques, AntConc et iTrameur, on est capable de justifier notre hypothèse sur « made in China ». En particulier, avec l’aide des concordances des mots, des cooccurrents des mots et des contextes autour des mots, on observe que dans le corpus chinois, les mots qui entourent le mot clé « 中国制造(made in China) » et qui apparaissent souvent avec eux sont généralement les mots qui incluent une émotion positive dedans. Ainsi, on pourrait dire que « 中国制造(made in China) » est plutôt positif en chinois.
Cependant, pendant le traitement, on peut trouver qu’il existent toujours des bruits qui dérangent l’analyse du corpus, trouver un bon moyen d’enlever ces bruits restent encore à discuter.

Analyse terminé. Merci pour votre lecture!
Meixin
