

Dans cet article l’analyse du corpus français généré à partir du script bash élaboré tout au long du projet. Le corpus du français s’il ne paraissait pas le plus difficile au premier abord à tout de même nécessité une attention particulière. Le problème majeur à surtout concerné les sites de forum très problématiques pour leur syntaxe récurrente comme le sujet qui est répété dans le titre de chaque intervention d’un internaute.
Pour l’analyse nous utilisons iTrameur (développé par Serge Fleury, Université Paris III) et AntConc (développé par Laurence Anthony, Waseda University), deux outils d’analyse textométrique.
Tout comme pour le corpus en italien, nous avons en premier lieu uniformisé tous les syntagmes équivalents à notre sujet : made in China. Cela s’est révélé particulièrement utile pour le corpus français qui contenait de nombreux syntagmes différents :
- made in China
- fabriqué en Chine
- fabriquée en Chine
- fabriqués en Chine
- fabriquées en Chine
- originaire de Chine
- provenant de Chine
- etc
Afin de rendre le corpus exploitable par iTrameur nous avons donc remplacé tous ces syntagmes par « made_in_china ». Cette opération a été effectuée en utilisant simplement la fonction rechercher/remplacer de notepad++.
Nous commençons sur AntConc : suite à un premier test, nous nous sommes rapidement rendu compte que la grande quantité de stopwords polluait considérablement notre corpus. Afin de pouvoir obtenir des résultats un minimum pertinents nous avons importé une liste de stopwords dans le logiciel afin qu’il les exclus automatiquement lors de l’analyse. On demande ensuite un index lexical, voilà ce que l’on obtient :


Le problème de cet index est que la grande majorité des mots qu’il rassemble est neutre, ils n’orientent pas vers un sentiment particulier. On remarque quand-même plusieurs mots signifiants « problèmes » « qualité » « produit » « luxe » « mauvaise » « prix » « vêtements » « mode » etc. Ces quelques mots nous informent sur les secteurs les plus cités sur le web « mode » « luxe » « vêtements » ainsi qu’une première orientation avec des mots comme « mauvaise » et « problèmes ».
Toujours sur AntConc nous effectuons maintenant une recherche par n-grams. En réglant l’affichage sur 5-grams les premiers résultats sont les suivants :
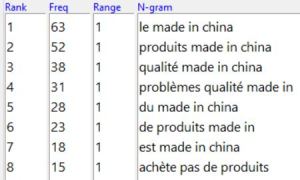
Nous retrouvons nos mots « problèmes » et « qualité » et nous observons cette fois qu’ils sont beaucoup plus signifiants. De plus, le rang 8 avec « achète pas de produits » renforce notre idée.
Nous passons maintenant sur iTrameur. Avant de continuer, précisons que le corpus a dû subir un nettoyage avant qu’il puisse être exploité par le iTrameur. D’abord rappelons que pour cet outil les stopwords ne sont pas ignorés. Mais le plus gros problème a surtout concerné les sites de forum. En effet certain ont une structure qui rappelle le titre du sujet a chaque intervention d’un internaute. Un simple exemple permet de comprendre le problème : Si dans le titre nous avons « produit made in china de mauvaise qualité » alors à chaque nouveau message cette ligne sera réécrite, souvent précédée d’un « RE: ». Dans ce cas les fréquences de mot présent dans ces sites sont complètement faussées. Une fois ces sites repérés dans le corpus nous avons éliminés ces lignes récurrentes grâce à la fonction rechercher/remplacer de notepate++.
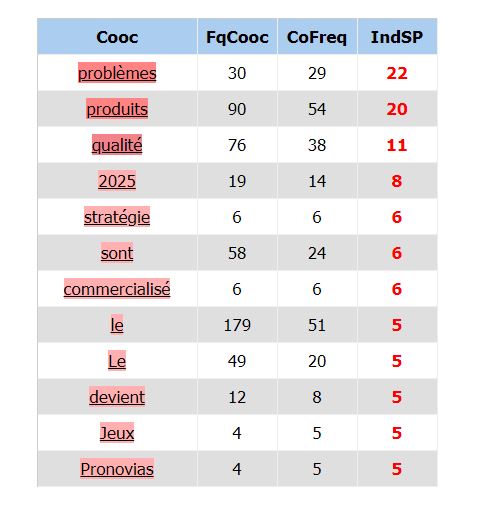
Une fois ce petit nettoyage effectué, nous programmons iTrameur pour obtenir les cooccurrences du syntagme « made_in_china ». Voici ce que nous obtenons :
TABLEAU :
LE GRAPHE ASSOCIE :
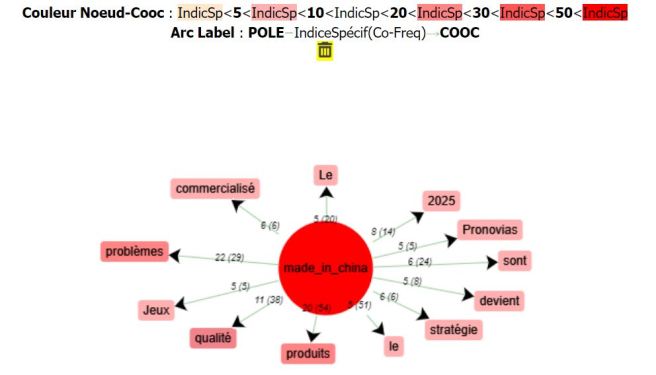
Comme prévu plusieurs stopwords sont ressortis : « Le », « sont », « devient » « le ». Nous en feront abstraction.
Concernant les autres mots, nous avons obtenus dans les trois premiers résultats des mots intéressants. « problèmes », « produits », « qualité ». D’abord nous pouvons dire que ces résultats sont tout à fait cohérents avec le premier logiciel.
Ensuite revenons à l’intuition que nous avions eu au début du projet : Nous pensions que les produits originaires de Chine étaient considérés comme de moins bonne qualité. il semblerait que les résultats obtenus jusqu’à présent confirment notre hypothèse.
Nous allons maintenant étudier chaque mot un peu plus en détails afin de valider ce que nous avançons.
2025 : En réalité nous savons déjà pourquoi nous obtenons ce résultat, il s’agit de quelques articles qui traitent de « made in china 2025 », un projet économique ayant pour objectif d’amélioration l’image des produits « made in china » à l’international. Si cette date ne nous apprend rien directement, nous pouvons néanmoins dire que le fait même de son existence prouve qu’il y a un besoin d’améliorer l’image négative des produits originaire de Chine.
Jeux : Il semblerait que le secteur le plus cité sur le web est celui des jouets. Cependant, ayant récupéré les données manuellement, nous connaissons leur contenu. Cette apparition semble assez bizarre pour que l’on procède à une vérification avec iTrameur.
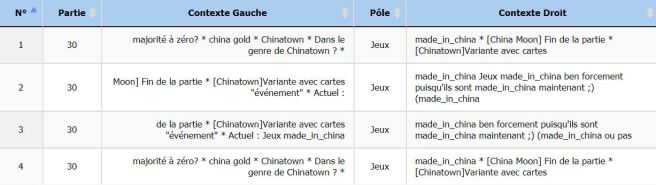
En réalité il s’agit d’une même partie. Il semble ici qu’il s’agisse d’un site de forum. Nous savons que les sites que nous avons retenus traitent d’autres secteurs commerciales. Si le mot « Jeux » est sorti avant les autres cela est certainement la cause de la taille, beaucoup trop limitée, de notre corpus. Le mot jeux est sans doute cité une quelques fois de plus dans ce site que les autres secteurs abordés dans leurs sites respectifs. De plus sa faible présence de 4 en fait un résultat négligeable.
problèmes : Le premier mot de nos résultats. Regardons ça de plus près.
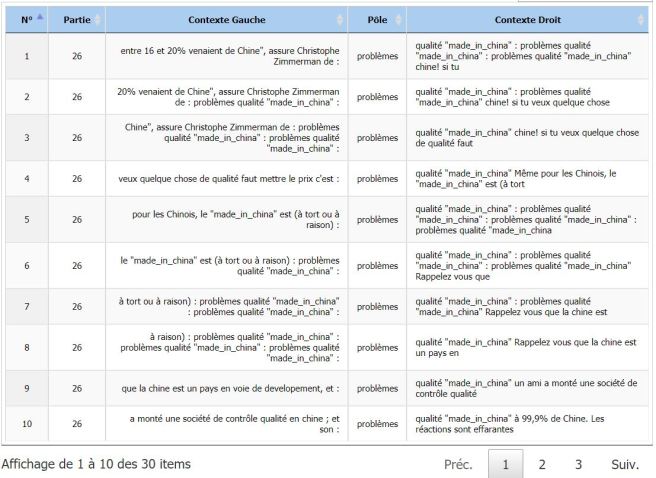
En réalité il s’agit ici aussi d’un même site. En l’occurrence un site de forum qui n’a pas été supprimé lors du nettoyage. Il s’agit d’un exemple parfait illustrant la difficulté que l’on peut avoir à analyser les informations contenues dans les sites de forum. Ici un seul site ayant répété le mot 30 fois a suffit pour erroner nos résultats. De plus, cette erreur est d’avantage marquée par la petite taille de notre corpus.
qualité : Seul ce mot paraît positif. Mais pour bien saisir comment il agit sur notre syntagme il faut étudier ses propres occurrences.
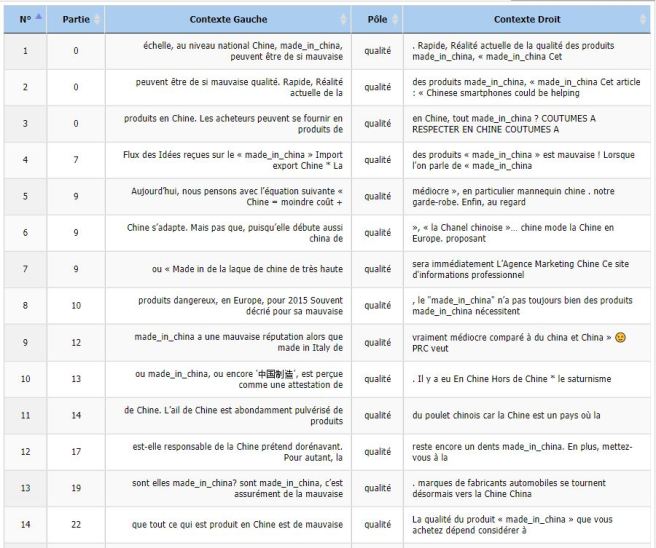

Après vérification sur les deux logiciels, on observe cette fois qu’il s’agit bien d’un mot provenant de contextes et de sites différents. Notons quand même que sa présence au coté du mot « problème » étudié précédemment augmente son résultat. Cependant sa présence dans de multiples autres sites montre qu’il aurait de toute façon été un des mots les plus fréquents.
Étudions maintenant ces cooccurrences afin de déterminer son influence :
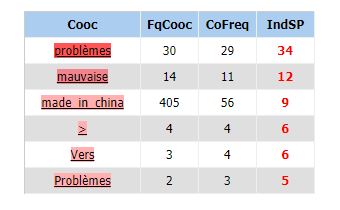
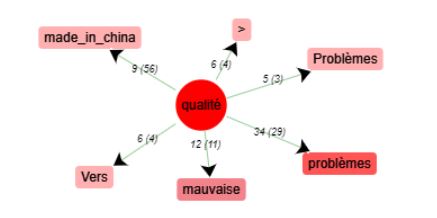
Nous excluons le mot « problème » comme expliqué précédemment. Nous obtenons donc directement l’adjectif « mauvaise ». Ainsi, nous sommes maintenant quasi-certains de valider notre hypothèse. Nous faisait une dernière vérification sur ce mot avec iTrameur.
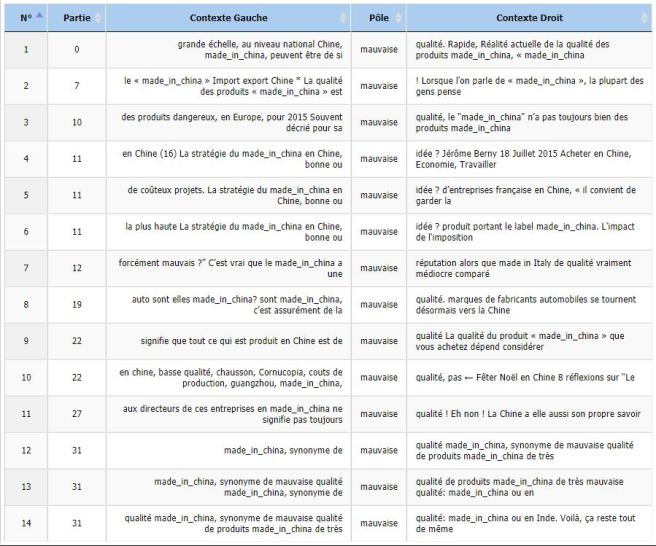
L’adjectif « mauvaise » provient bien de contextes différents. Nous pouvons maintenant affirmer que l’idée de « mauvaise qualité » est majoritairement attribuée aux produits « made in China ». Il faut cependant relativiser ces résultats puisqu’ils sont orientés par un très faible nombre de sites qui contiennent ces cooccurrences en très grandes quantités. Ce qui se fait d’avantage sentir lorsque nous travaillons sur un corpus de petites tailles.
Analyse terminée !
Pierre
