

Dans cette séance, nous cherchons à mieux détecter l’encodage des urls. En effet avec la méthode utilisée dans le script précédent certains encodages n’ont pas été détectés alors que le code HTTP est valide. On verra également comment convertir les pages non UTF-8.
Environnement (Meixin) : Système : Windows / Editeur : Notepad ++
Résumé de l’état du script :
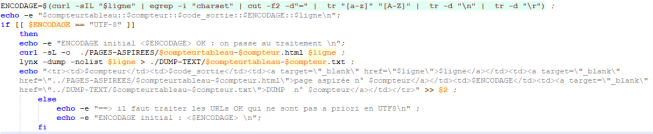
Actuellement pour les urls au code HTTP 200, on passe à la détection de l’encodage. Pour l’extraire on utilise l’enchaînement de commandes qui permet de stocker dans une variable l’encodage déclaré dans les codes sources des pages html que l’on souhaite aspirer.
ENCODAGE=$(curl -I « $ligne » | egrep -i ‘charset’ | cut -f2 -d’=’ | tr ‘[a-z]’ ‘[A-Z]’)
Pour chaque URL (« $ligne ») contenue dans nos fichiers URL on cherche à connaître les informations d’en-tête contenues dans le code source html avec la commande « curl -I ». Puisque la seule information qui nous intéresse est l’encodage on ajoute egrep -i « charset » pour obtenir uniquement la ligne de l’information. Ensuite avec cut -f2 -d’=’, on « découpe » et garde seulement le contenu qui suit « charset= ». Enfin on uniformise avec « tr [‘a-z’] [‘A-Z’] ».
Si l’encodage est UTF-8 alors on aspire la page au format html avec « curl -o » et au format txt avec « lynx -dump ». Dans le cas contraire, nous allons voir comment nous pouvons éventuellement convertir en UTF-8. Cependant nous remarquons que certains encodages n’ont pas pu être récupérés, il semblerait qu’il s’agisse des encodages non déclarés ou mal déclarés dans le code html. En effet, notre méthode suppose que tout ait été déclaré correctement.
I. Evolution du script : les commandes file et iconv.
1. La commande file
Avant toute chose, nous devons donc forcer la détection de l’encodage des pages valident. La commande qui permet de réaliser cette fonction est file :
La commande file : Elle permet de récupérer l’encodage automatiquement. Cependant si dans un premier abord cette commande peut paraître extrêmement utile, nous verrons dans la suite du projet qu’elle n’est pas forcement fiable. Ceci explique notamment pourquoi nous ne l’utilisons pas en premier recours.

2. La commande iconv
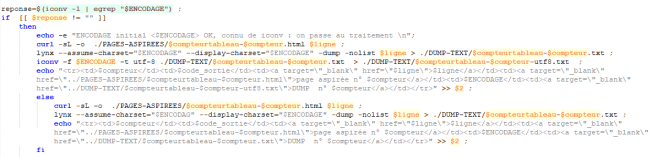
Maintenant que nous avons réussi à récupérer l’encodage de toutes les pages valides, nous devons convertir les pages qui ne sont pas encodées en UTF-8. La commande qui permet cette fonction est iconv.
Pour convertir nous utilisons deux options :
- -f qui indique l’encodage d’entrée à convertir
- -t qui indique en quel encodage il doit convertir
D’abord nous vérifions que iconv reconnait l’encodage. S’il le reconnait alors nous pouvons le convertir. Si iconv ne le reconnait pas alors nous devrons trouver une autre solution.
Le script complet est :
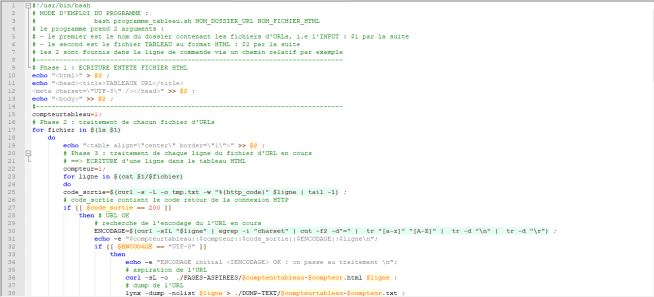

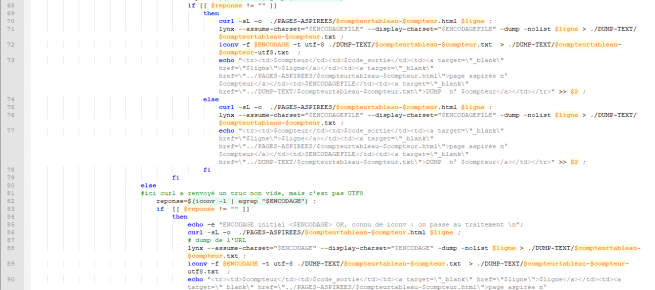
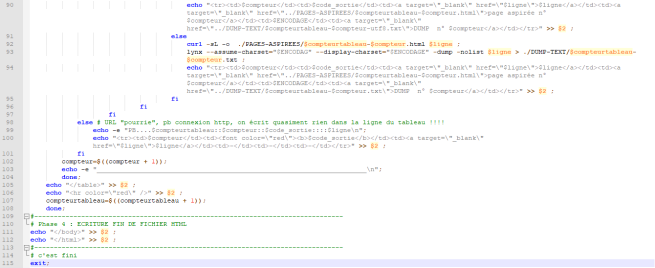
Exécution du script dans le terminal :

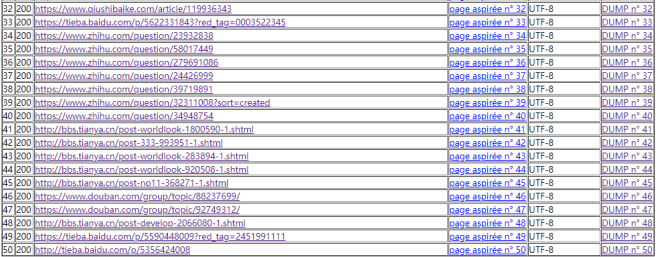
Nous obtenons le tableau ci-dessous :

Nous pouvons synthétiser le processus de l’algorithme par le schéma suivant :

II. Les problèmes rencontrés
1. Pour les URLs dont l’encodage s’affiche « GBK »

url: http://news.163.com/09/0729/17/5FDIP8U600013HPO.html
Observons le processus dans le terminal :
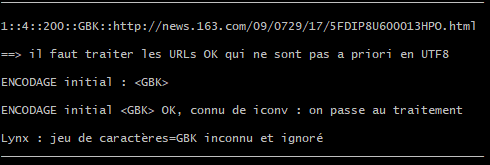
L’encodage détecté est GBK, cependant en vérifiant l’encodage avec le navigateur, nous lisons « charset=gb2312 ». Le programme n’arrive donc pas à identifier le « gb2312 ». De plus, même si iconv l’identifie en tant que GBK, il n’arrive pas à le convertir en UTF-8. De même lynx ne fonctionne pas non plus avec le « GBK ».
2. Pour les urls dont l’encodage s’affiche « UNKNOWN-8BIT »

url: http://news.mydrivers.com/1/239/239959.htm
Observons le processus dans le terminal :
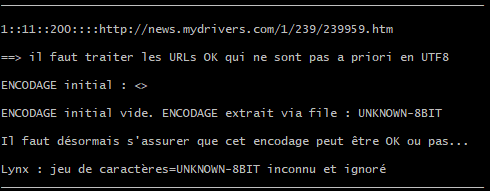
L’encodage est définie comme étant « UNKNOWN-8BIT ». On remarque que ni iconv, ni lynx ne fonctionnent. Cependant si on vérifie dans le code source HTML on observe que la page est encodé correctement en UTF-8.

On suppose que c’est la méthode d’écriture du langage HTML qui empêche l’identification de l’encodage. Si le « content » et le « charset » étaient écrits séparément, cela faciliterait l’extraction de l’encodage.
3. Pour les URLs dont l’encodage s’affiche « ISO-8859-1 »

url: http://shzw.eastday.com/shzw/G/20171203/u1ai11042557.html
Observons le processus dans le terminal :
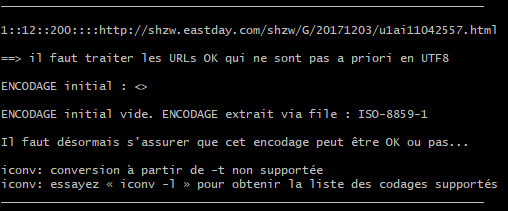
L’encodage détecté est « ISO-8859-1 ». Cependant la conversion de « ISO-8859-1 » vers UTF-8 n’est pas supportée par iconv. De plus, le DUMP-TEXT est mal encodé. En vérifiant l’encodage dans le code source, nous obtenons :
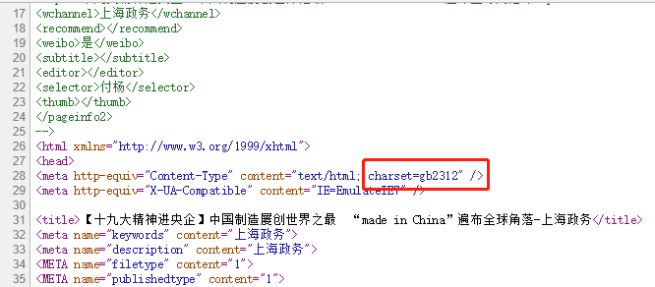
4. Pour les URLs dont l’encodage s’affiche « UTF-8 »
Même si l’encodage détecté est « UTF-8 », le DUMP-TEXT récupéré est mal encodé. On cite l’exemple ci-dessous:

https://baike.baidu.com/item/%E4%B8%AD%E5%9B%BD%E5%88%B6%E9%80%A0/6000?fr=aladdin
Observons le processus dans le terminal :
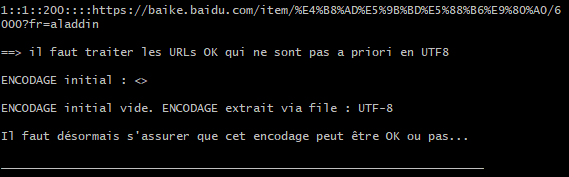
La commande file a détecté un encodage « UTF-8 ». En revanche la récupération DUMP-TEXT n’a pas été effectué en UTF-8. Il semblerait que ce problème concerne un grand nombre d’URLs en chinois.
***
Nous travaillons actuellement à la résolution de ces problèmes !
Meixin, Andréa et Pierre
